Project Overview
Our group project focused on analyzing Airbnb listings in New York City using statistical and machine learning techniques. The main goal was to explore the factors affecting listing prices and guest engagement, and to segment the market using both exploratory data analysis (EDA) and models such as linear regression and K-Means clustering.
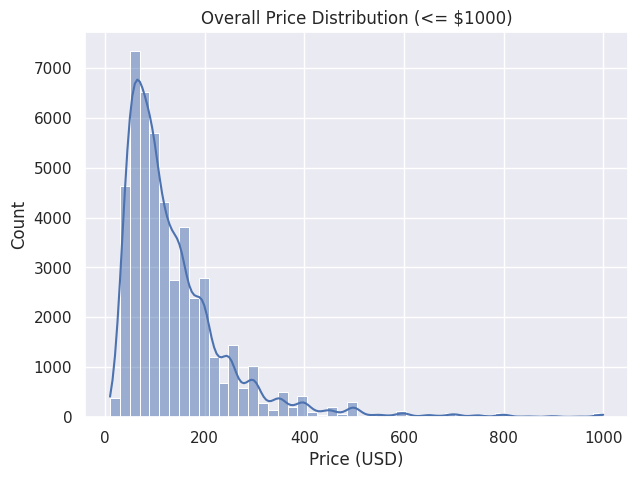
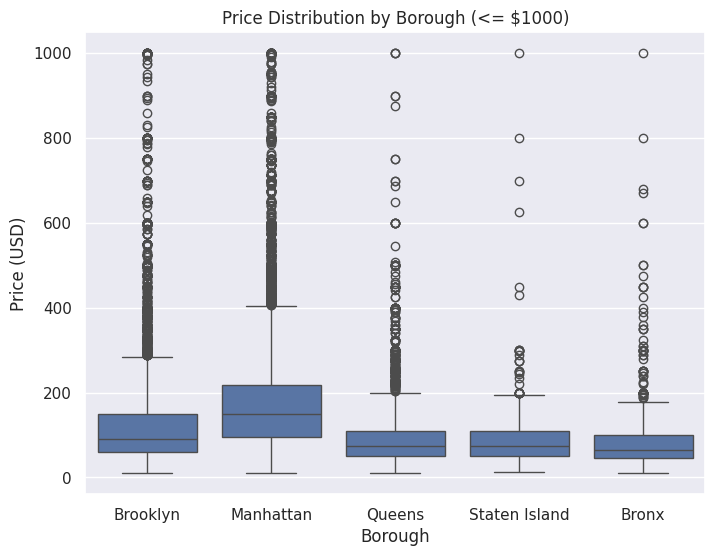
The final report, titled "Machine Learning Analysis of Airbnb Listings in New York City", was a collective effort. During the early phase of the project, we all contributed to the EDA, testing different visualizations and statistical summaries. For the final report, we selected elements from all members' work in the EDA stage, especially visualizations that clearly communicated the distribution of prices and review patterns across neighborhoods.
My Main Contribution: K-Means Clustering
I was responsible for implementing the clustering approach that segmented NYC neighborhoods by average listing price and average number of reviews per listing.
My contributions included:
- Aggregating the dataset by neighborhood to calculate relevant metrics
- Normalizing the variables to ensure proper clustering performance
- Testing different values of
kusing:- The Elbow Method
- Silhouette Analysis
- Visualizing the resulting clusters and profiling each group
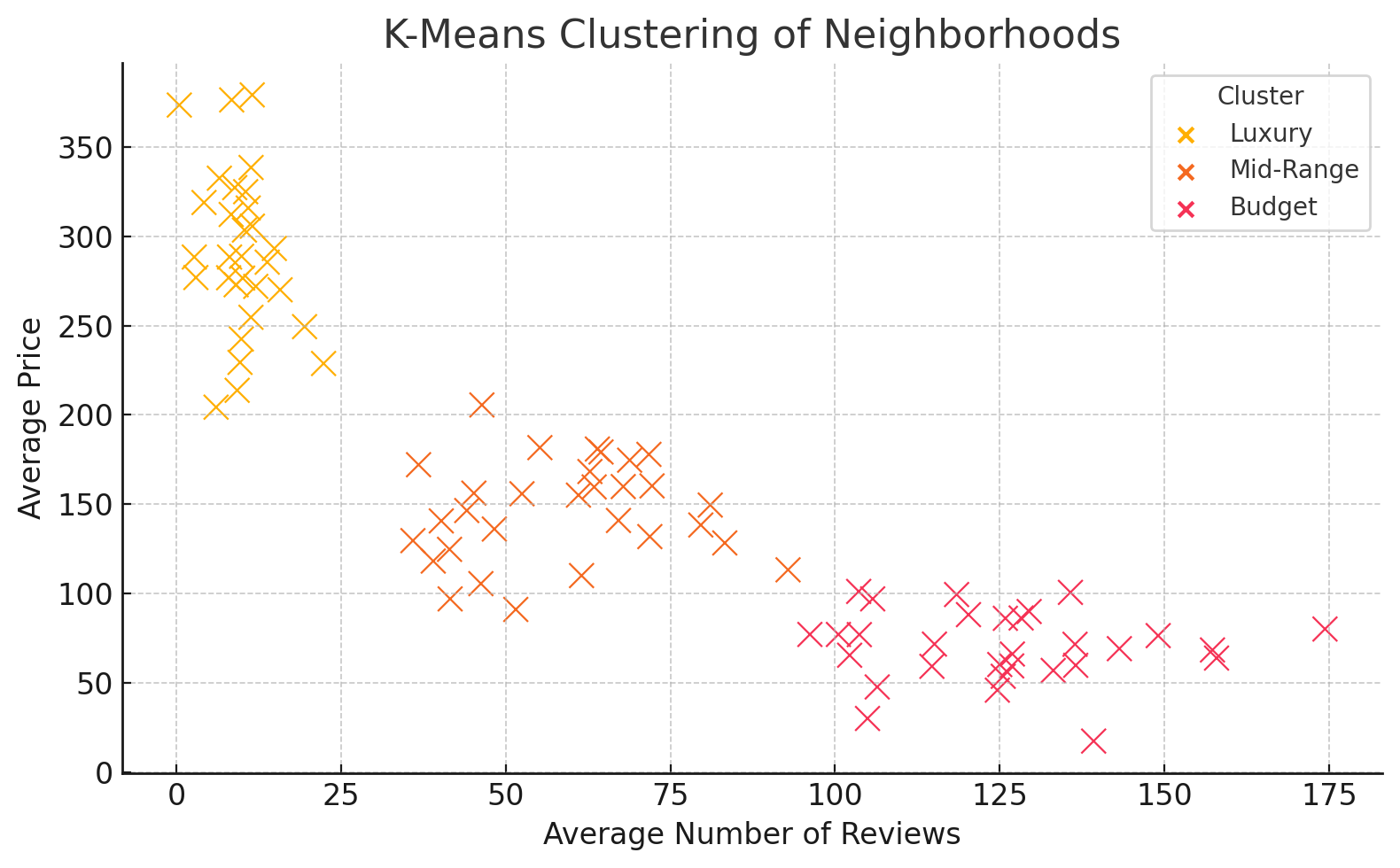
Identified Clusters
Reflection and Learning
This task strengthened my understanding of unsupervised learning and practical clustering applications in a real-world context. I developed skills in:
- Data aggregation and normalization for machine learning
- Interpreting cluster patterns and validating them
- Integrating visuals and code into a team project workflow
Additionally, the project gave me hands-on experience working collaboratively on a technical analysis, aligning individual contributions within a cohesive team deliverable.